Machine Learning (ML) offers exciting possibilities for innovative products and improvements of existing services. To avoid negative consequences, such as the loss of costumer data or commercial secrets, it is important to consider security and privacy aspects before applying Machine Learning in real-world applications.
SBA Research conducts research in the area of privacy-preserving Machine Learning and develops novel solutions to mitigate related threats. In addition, we offer trainings and expert discussions on implications and available defense mechanisms as well as consulting services in the area of secure and privacy-preserving data management and ML.
Topics include:
- Protection against theft of intellectual property (data or trained ML models)
- Defense mechanisms against adversarial attacks
- Privacy-preserving computation methods like federated learning and secure multi-party computation
- Novel methods for data anonymization, including complex data types
Read our Blog on Privacy & Security in ML!
This content is locked.
By loading this content, you accept YouTube's privacy policy.
https://policies.google.com/privacy






Research
Machine Learning (ML) offers exciting possibilities for innovative products and improvements of existing services. To avoid negative consequences, such as the loss of costumer data or commercial secrets, it is important to consider security and privacy aspects before applying Machine Learning in real-world applications.
SBA Research conducts research in the area of privacy-preserving Machine Learning and develops novel solutions to mitigate related threats. In addition, we offer trainings and expert discussions on implications and available defense mechanisms as well as consulting services in the area of secure and privacy-preserving data management and ML.
Topics include:
- Protection against theft of intellectual property (data or trained ML models)
- Defense mechanisms against adversarial attacks
- Privacy-preserving computation methods like federated learning and secure multi-party computation
- Novel methods for data anonymization, including complex data types
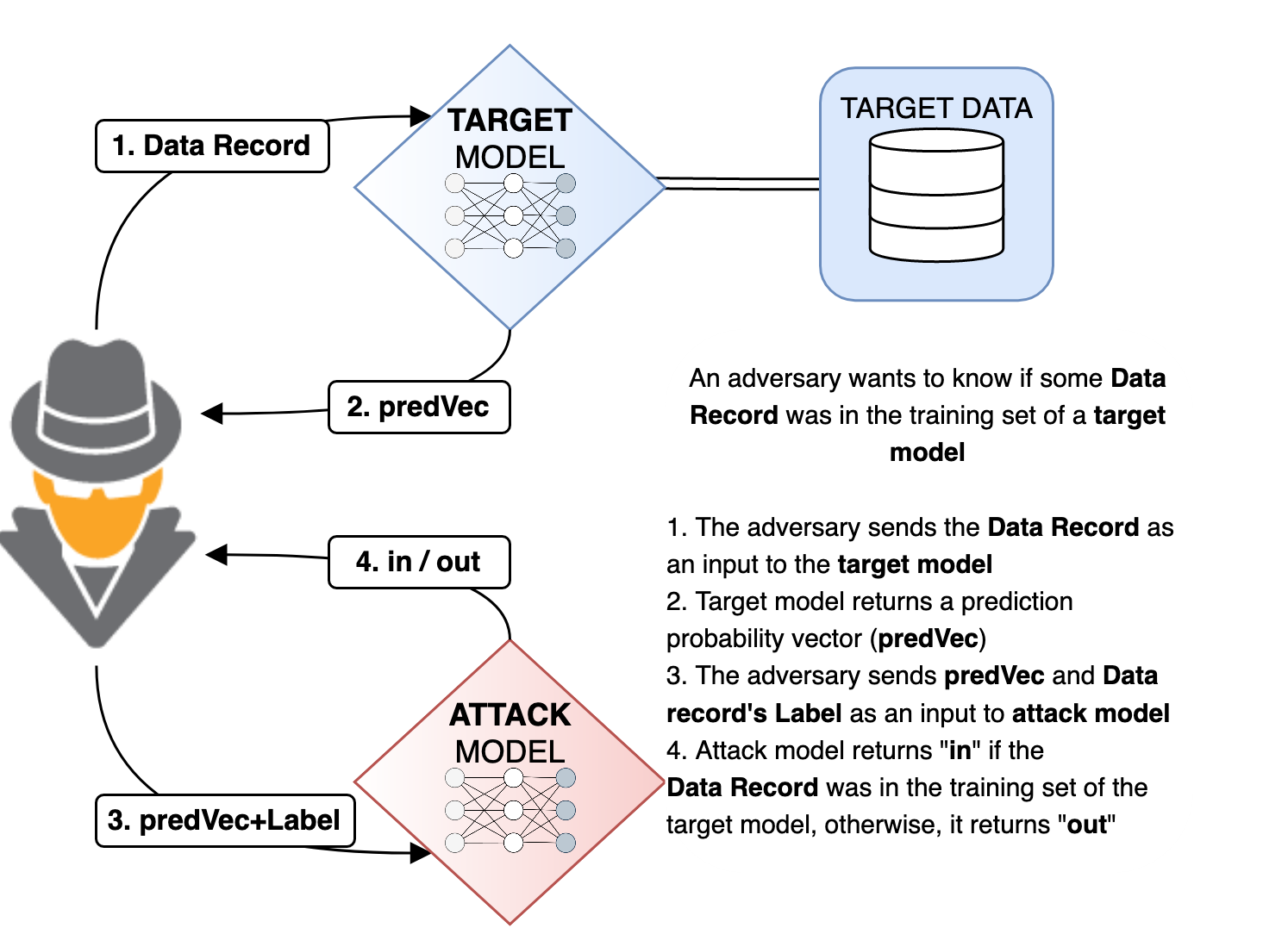
With regards to data processing, preserving the privacy of individuals and protecting business secrets is highly relevant for organizations which are working with sensitive and/or personal data. In particular, if companies outsource ML models to external (cloud) providers to analyze their data, they have to consider privacy-preserving data analysis. Data anonymization or -synthetization are possible solutions for privacy protection. A further threat that has to be considered is an adversary recovering training data directly from ML models. SBA Research addresses how organizations can collaboratively build ML models while not directly sharing their data and guaranteeing privacy for their customers.
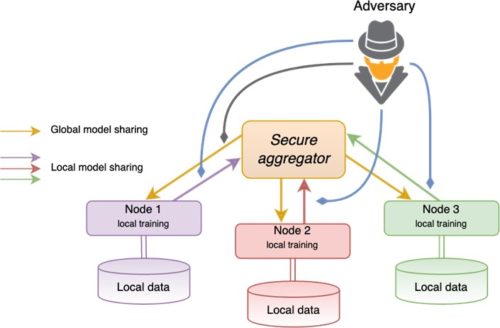 Automated decision making can have a significant influence on individuals and groups; hence, the robustness of the respective algorithms is of great concern when deploying such systems in real-world applications. Various types of attacks can trick a ML system into making wrong predictions. Backdoor attacks, for instance, poison the training data by injecting carefully designed (adversarial) samples to compromise the whole learning process. In this manner it is possible to, for example: cause classification errors in traffic sign recognition with safety critical implications on autonomous driving; evade spam filters; manipulate predictive maintenance; or circumvent face recognition systems.
Automated decision making can have a significant influence on individuals and groups; hence, the robustness of the respective algorithms is of great concern when deploying such systems in real-world applications. Various types of attacks can trick a ML system into making wrong predictions. Backdoor attacks, for instance, poison the training data by injecting carefully designed (adversarial) samples to compromise the whole learning process. In this manner it is possible to, for example: cause classification errors in traffic sign recognition with safety critical implications on autonomous driving; evade spam filters; manipulate predictive maintenance; or circumvent face recognition systems.
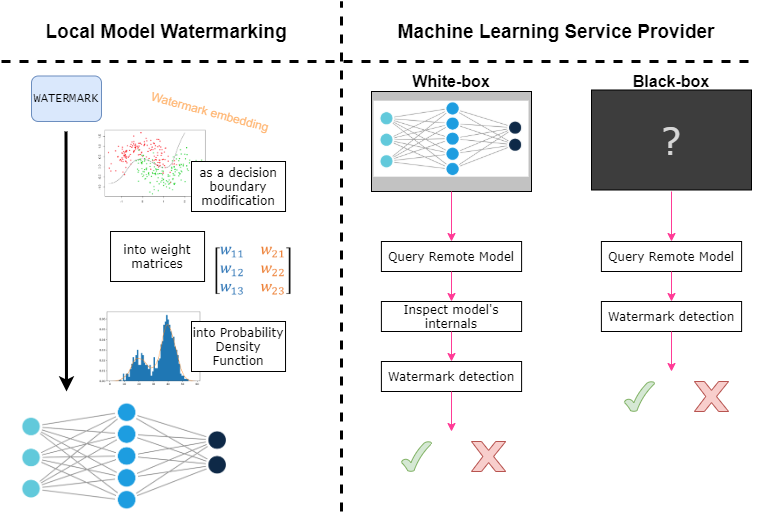
Developing methods to detect and defend against these attacks is an important research topic for SBA Research.
Downloads
- Poster: RDA DMP Common Standard for Machine-actionable Data Management Plans
- Poster: Synthetic Data - Privacy Evaluation and Disclosure Risk Estimates
- Poster: Synthetic Data - Utility Evaluation for Machine Learning
- Poster: Data Poisoning Attacks in Federated Learning
- Poster: Federated Machine Learning in Privacy-Sensitive Settings
- Poster: Fingerprinting Relational Data Sets






















