Evolving and Securing of Knowledge, Tasks and Processes in Distributed Dynamic Environments via a 2D-Knowledge/Process Graph
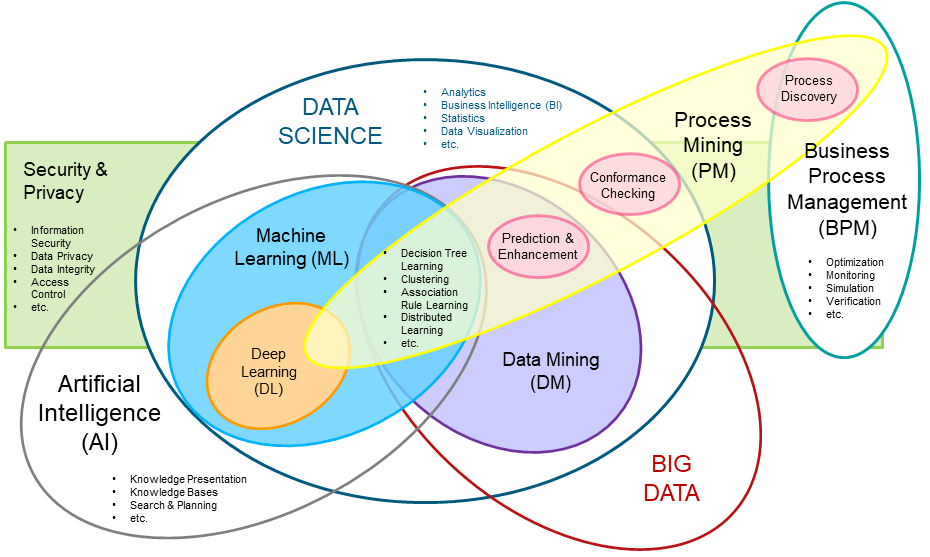
Within this project, we develop mechanisms for process mining in a distributed setting, i.e. where the process is not executed within a single company, but collaboratively worked on together. Process mining thus is limited to the information that can be exchanged. We aim at increasing that, by on the one hand investigating fitting anonymisation methods, and on the other hand learn from the data in a distributed setting.
Motivation
Creative work hardly follows prescribed processes. It is characterized by flexibility and interaction. Often the work is distributed over several, autonomous persons or groups. As an example, a registration of a patent in several countries could involve the company of the inventor, a patent attorney in the country of the inventor, a graphic designer, a translator and a patent attorney in one of the other countries. The following patent registration could be completely different, but both processes came to the same result, the patent registration. Even modern software systems that support creative work are by far too restrictive. The problem is that processes and workflows have to be defined in advance. This takes time and it is nearby impossible to foresee all, even future variants. Even more, there can exists alternative ways to reach a goal.
Project Outline
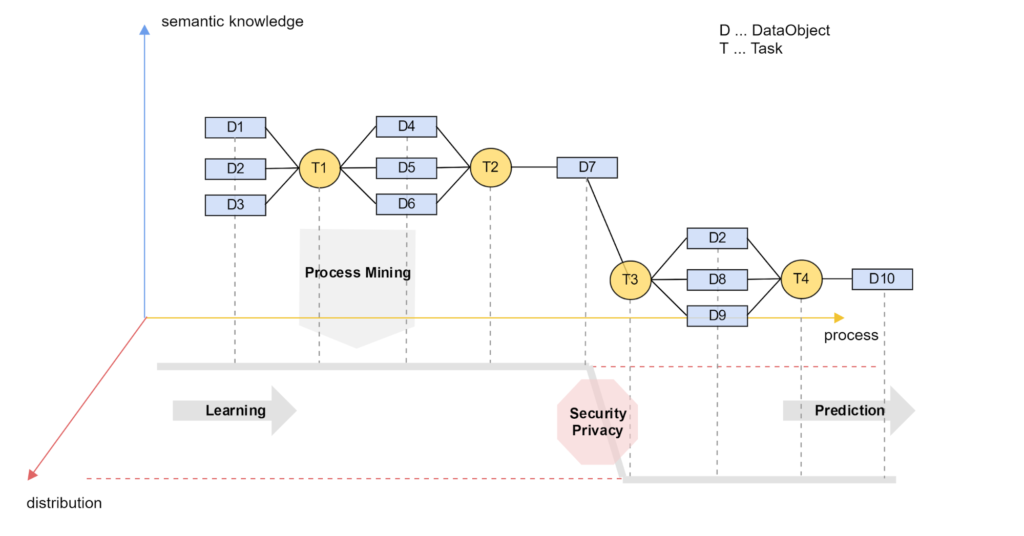
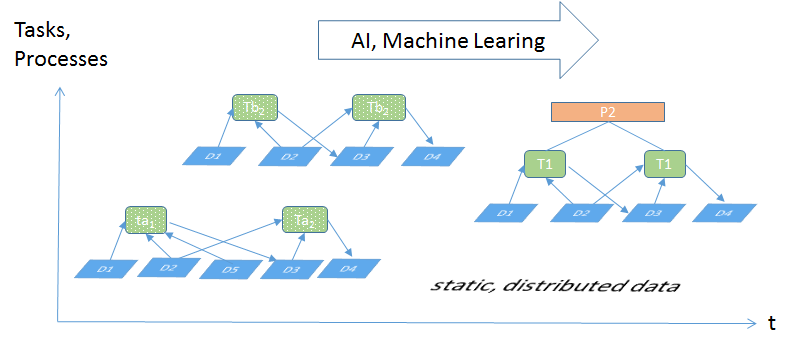
Within this project we follow a bottom-up-approach. During creative work the system records which digital artefacts (e.g. documents, figures, e-mails) and which information are taken as input to produce which new artefacts. Step by step tasks, workflows and business processes shall be learned from the relations between the artifacts. This shall be realized by using current methodologies and techniques from the areas of machine learning, process mining and artificial intelligence in general. As a central data structure a two-dimensional (2D) Knowledge/Process Graph shall be used. Finally such a system not only autonomously structures the data and knowledge base without redundancies but also continuously learns new processes. Process definitions done by humans – the main problem of current systems – would become completely obsolete. Additionally, the knowledge base grows autonomously in the background and is up-do-date at any time.
Project Consortium
A consortium consisting of four partners, SCCH – Software Competence Center Hagenberg (project management, process mining, machine learning), SBA Research (distribution and privacy), FAW – Institut für Anwendungsorientierte Wissensverarbeitung (knowledge modelling, access control) und polymind (software for knowledge workers, knowledge modelling), plans to answer this research questions and to evaluate the solutions with real world data. polymind intends to include the results in their future software.
Related News & Events
Contact
This project is funded by the FFG.